The project (Algo)rhythmic Refrains was implemented within the framework of this thesis by using a Long Short-Term Memory (LSTM) recurrent neural network (RNN) that with the original intent to train it with the entries from Eva Hesse’s diaries in order to produce new entries resembling those from the diary. Even if the diaries were published as a book, using someone’s diary entries as a dataset resembled data harvesting by tech giants to train and tune their models. This particular model was chosen since it works well for modelling sequences, here language modelling, due to its ability to “remember” or “forget” parts of the training data, which enables it to recognise long-term temporal dependencies in data and extract grammatical structure. While much more could be said about the model mentioned above, it was neither developed nor implemented as the part of thesis, but was “chosen” by the author from GitHub, just like Obvious Collective did. GitHub is an online platform for version control of coding frameworks. It holds countless repositories of code, notably machine learning code, most of them free to use and modified according to open-source principles. Open-source principles usually involve many developers working decentralised, checking and approving the quality of contributions to the existing code. They also enable auditing of the code for security, discovering possible bugs, and making it almost impossible to build back doors for exploitation. None of the code was modified. Only new data was fed into the network with minimal changes to the initial parameters into an open-source model. But the original intent of (Algo)rhythmic Refrains shifted from generating credible diary entries by feeding as much data as possible into the network into a task of giving the algorithm as little data as the model can handle, driving it to its limit before it reaches the breaking point. Not in order to break it but to examine what it does at the edges of its functioning. Due to the small training sample, the result bore no resemblance to Hesse’s diary entries from the original data set.
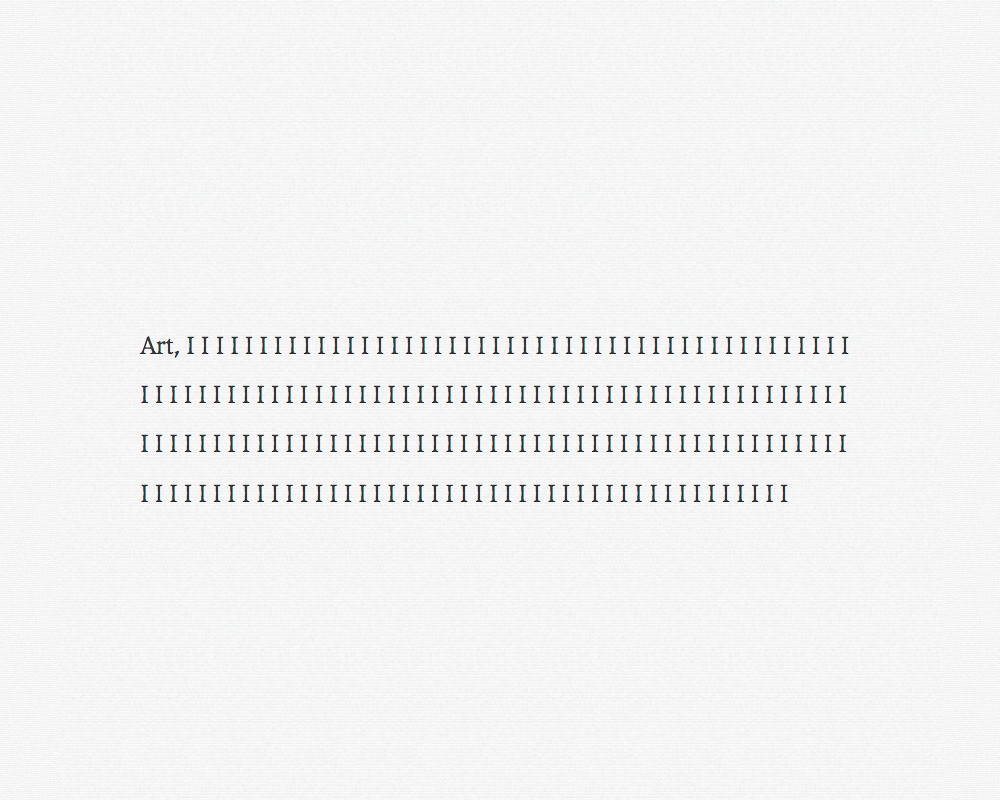
With just a few diary entries, the algorithms created an entry starting with “Art”, followed by more than 150 “I”s. While both words were expected to be frequently used in an artist’s diary, the result does not represent the actual frequency of their occurrence. The “memory cell” reached a certain threshold, preventing the model from exiting the cell. While it produced nothing nearly remote to a diary entry, it revealed a tic that would have never appeared with a more extensive training set—a tool hidden in a tool. To emphasise the rhythm present in the entry, the text was fed into Google's text-to-speech algorithm to create an algorithmic speech version of it:
The next iteration with a more extensive (and still minuscule data set when it comes to training machine learning models) started to reveal how the algorithm is intended to work, forming a sentence that is still entirely dominated by the repetition tic:

And a yet-another speech translation yielded:
In the last iteration, with another expansion of the dataset, the repetition tic remains present but not dominant anymore, waiting to be swallowed by the discourse. It would be ridiculous to assign artistic agency or creativity to the side of the algorithm in the case of (Algo)rhythmic Refrains. And yet, something emerges from unexpected results, something that was only obvious with the algorithmic processing of the LSTM network at the limit of its usability. That something is what Lyotard calls “undoing the code”, which “consists entirely in the transgression of the measured intervals underpinning the weave of language [langue], and is thus, indeed, ‘fulfilment of desire’”. It works precisely because it barely works, neither entirely random nor fully intentional, a work of algorithmic memory cell, holding a trace of linguistic structure fed to it via textual data set, which, when stuck in repetition, pushed discourse on the verge of libidinal, forming a figure of refrain. Serendipity, yet another of Duchamp’s valued tools, had a finger in this algo-human pie too: in all three refrains, memory cells that triggered the model into repetition contained signifiers of dialectical concepts: “I” as Identity, “the other” as Alterity, and “not” as Negation. The LSTM algorithm, as if choking on dialectics, accidentally pointed to repetition as desistance of a mere representation against “yet-another-diary-entry”, something Deleuze and Guattari knew all along: “The T factor, the territorialising factor, must be sought elsewhere: precisely in the becoming-expressive of rhythm or melody, in other words, in the emergence or proper qualities (colour, odour, sound, silhouette\ldots) Can this becoming, this emergence, be called Art?”

In the further instalment of the project, particularly for the Entanglement: the Opera, the entry was "recited" by Google’s text-to-speech algorithm, accompanied by the overture from the opera Parsifal by Wilhelm Richard Wagner first premiered in 1882. To avoid and license fees, a public domain recordings from 1927 was used which coincided with the rise of Nazi party to power in Germany. Both the association of Wagner’s music with Nazis as well as the date of the recording give this work the uncanny feeling. It raises the question of whether artificial intelligence (primarily a good old fashioned AI, which possess no embodiment in the real world and is trained in the vacuum) is inherently fascist, or at least has potential to it.